
What is the definition of code obfuscation?
The process of changing an executable so that it is no longer valuable to a hacker while remaining fully functional is known as code obfuscation. While the procedure may change method instructions or metadata, it has no effect on the program’s output. To be clear, practically any code can be reverse-engineered given enough time and effort. On various platforms, such as Java, Android, iOS, or.NET (e.g. Xamarin, C#, VB.NET, F#), free decompilers can quickly and painlessly reverse-engineer source code from an executable or library. Reverse-engineering a program is complex and expensive due to automated code obfuscation.
What is the purpose of a Code Obfuscator?


You can safeguard against trade secret (intellectual property) theft, unauthorized access, evading licensing or other limitations, and vulnerability discovery by making an application considerably more difficult to reverse-engineer.
What is the Process of Obfuscation?
Code obfuscation is made up of a variety of approaches that work together to form a layered defense. It works best with languages like Java or.NET languages like C#, VB.NET, Managed C++, F#, and others that generate intermediate level instructions. The following are some examples of obfuscation and application security techniques:
Obfuscation should be renamed.
The names of methods and variables are changed when they are renamed. It makes the decompiled source more difficult to understand for humans, but it has no effect on program execution. Different schemes, such as “a,” “b,” “c,” or numbers, unprintable characters, or invisible characters, can be used in the new names. And, as long as the names have different scopes, they can be overloaded. Most.NET (C#, etc.), iOS, Java, and Android obfuscators use name obfuscation as a basic transform.

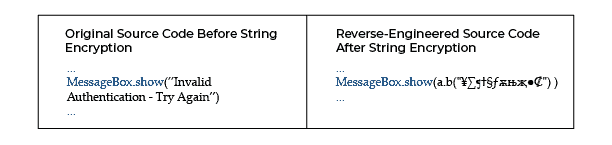
Encryption of Strings
All strings are discoverable and readable in a controlled executable. Strings can be used to discover essential code parts by checking for string references inside the binary, even if methods and variables are renamed. This includes messages that are displayed to the user (particularly error messages). String encryption hides strings in the executable and only restores their actual value when needed to offer an effective barrier against this type of assault. Decrypting strings at runtime usually results in a modest performance hit.
Obfuscation of Control Flow
Conditional, branching, and iterative components are synthesized in control flow obfuscation to provide acceptable executable logic but non-deterministic semantic consequences when decompiled. Simply put, it turns decompiled code into spaghetti logic, which is extremely difficult for a hacker to understand. These strategies may have an impact on a method’s runtime performance.

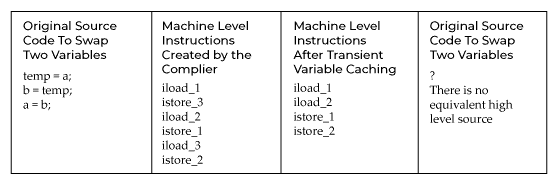
Transformation of Instruction Patterns
Converts the compiler’s common instructions to other, less evident constructions. These are totally legal machine instructions that may or may not transfer cleanly to high-level languages like Java or C#. Transient variable caching, for example, takes use of the stack-based structure of the Java and.NET runtimes.
Inserting a Dummy Code
Inserting code into an executable that has no effect on the program’s logic but breaks decompilers or makes reverse-engineered code significantly more difficult to understand.
Metadata and unused code should be removed.
Debug information, non-essential metadata, and utilized code are removed from applications, making them smaller and limiting the amount of information available to an attacker. This approach may enhance runtime performance marginally.
Merging/Binary Linking
Multiple input executables/libraries are combined into one or more output binaries with this transform. Linking can help you reduce the size of your application, especially when combined with renaming and pruning. It can also make deployment circumstances easier and minimize the amount of information available to hackers.
opacity Predicate Insertion obfuscates by introducing conditional branches that always evaluate to known results—results that are difficult to predict using static analysis. This is a method of inserting potentially wrong code that will never be executed but will be perplexing to attackers attempting to decipher decompiled output.
Anti-tampering technology
An obfuscator can inject application self-protection into your code to ensure it hasn’t been altered with. If tampering is discovered, the application can be shut down, its functionality limited, random crashes (to hide the cause of the crash), or any other specific action taken. It may also send a message to a service informing it of the detected tampering.
Debug-Prevention
When a hacker wants to pirate or counterfeit your app, steal your data, or change the behavior of a vital piece of infrastructure software, they’ll almost definitely start by reverse engineering and debugging it. By injecting code to identify if your production application is running in a debugger, an obfuscator can layer in application self-protection. If a debugger is utilized, it can damage sensitive data (to prevent theft), cause random crashes (to hide the fact that the crash was caused by a debug check), or execute any other specific action. It may also send a message to a service in order to provide a warning signal.
Is it necessary for me to disguise my application?
If you distribute software that has intellectual property, allows access to sensitive information, or has gated functionality and operates in an untrusted environment, you should strongly consider using obfuscation and runtime app self-protection. Attackers will have a significantly harder time deciphering the code and analyzing the program if it is obfuscated.
It also makes debugging and tampering with your program more difficult for hackers. The ultimate goal is to provide a layer of security that makes it difficult to extract or find useful information from an application, such as trade secrets (IP), credentials, or security vulnerabilities. It should also make it more difficult to change the logic of a program or repackage it with harmful code.








{kind=link}